Learning to Act from Actionless Videos
through Dense Correspondences


We train our video generation model on the Bridge data (Ebert et al., 2022), and perform evaluation on a real-world Franka Emika Panda tabletop manipulation environment.











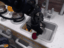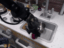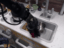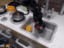
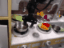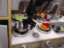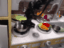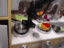

















We train our video generation model on 165 videos of 11 tasks. We evaluate on robot manipulation tasks in Meta-World (Yu et al., 2019) simulated benchmark.





























We train our video generation model on 240 videos of 12 target objects. We evaluate on object navigation tasks in iTHOR (Kolve et al., 2017) simulated benchmark.
































We train our video generation model on ~200 actionless human pushing videos and evaluate in Visual Pusher (Schmeckpeper et al., 2021, Zakka et al., 2022) robot environment.












We show that our video diffusion model trained on Bridge data (mostly toy kitchen) already can generalize to complex real-world kitchen scenarios. Note that the videos are blurry since the original video resolution is low (48x64).



We compare our proposed first-frame conditioning strategy (cat_c) with the naive frame-wise concatenate strategy (cat_t). Our method (cat_c) consistently outperforms the frame-wise concatenating baseline (cat_t) when training on the Bridge dataset. Below we provide some qualitative examples of synthesized videos with 40k training steps.






This section investigates the possibility of accelerating the sampling process using Denoising Diffusion Implicit Models (DDIM; Song et al., 2021). To this end, instead of iterative denoising 100 steps, as reported in the main paper, we have experimented with different numbers of denoising steps (e.g., 25, 10, 5, 3) using DDIM. We found that we can generate high-fidelity videos with only 1/10 of the samplimg steps (10 steps) with DDIM, allowing for tackling running time-critical tasks. We present the synthesized videos with 25, 10, 5, 3 denoising steps as follows.



















































































































